Fraud Capture: Identity Theft from a Data Science Perspective
In 2022, 1.1 million incidents of identity theft were reported through the Federal Trade Commission, resulting in $8.8 billion lost to fraud. Not only does this cost individuals and businesses money, but it also decreases trust between people and the companies they interact with.



In 2022, 1.1 million incidents of identity theft were reported through the Federal Trade Commission, resulting in $8.8 billion lost to fraud (1). Not only does this cost individuals and businesses money, but it also decreases trust between people and the companies they interact with. So, how can we stop bad actors without adding friction to good users in the digital world? While our goal is to prevent fraud, we still need to ensure that good consumers have as seamless of an experience as possible. The more extensive the sign-up process is for a product or service, the higher the drop-off rate, so the process must be as simple as possible.
Prove helps combat fraud by performing digital identity authentication and fraud mitigation using phone risk signals and associating identities to phone numbers to catch bad actors before they can commit fraud. Prove performs digital authentication and identity verification via a solution termed “PRO.” Much of this occurs behind the scenes, allowing the user to have a seamless experience.
PRO

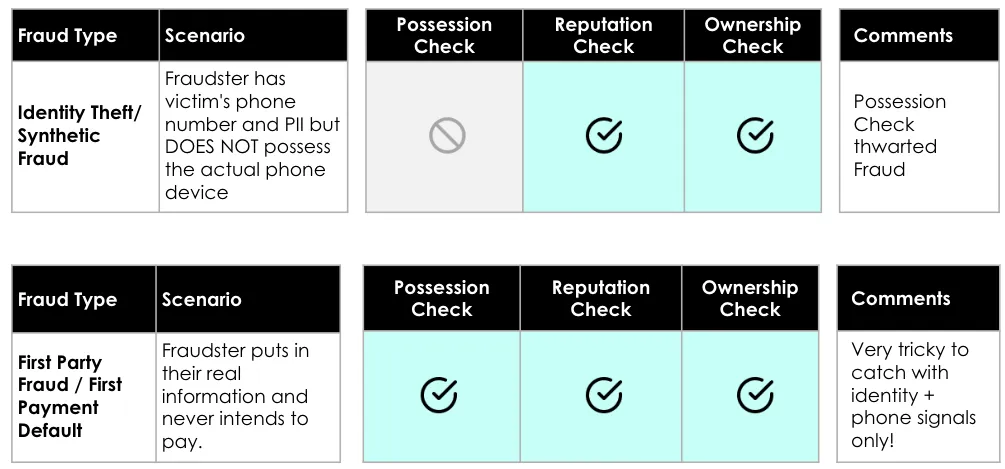
PRO stands for Possession, Reputation, and Ownership, of which we are referring to a telephone. We check to see whether the person claiming to be using the phone is actually in possession of it (Possession), what the recent activity on that phone looks like (Reputation), and whether the person SHOULD have access to the phone (Ownership).
The first part of Prove’s solution is built on well-established cryptographic protocols SIM and FIDO. Prove utilizes a cryptographic bind-based authentication where the phone number is bound to the SIM with 128-bit encryption, allowing Prove to authenticate that the user is actually in possession of the phone at the time of the transaction. I’ll go into the importance of this later on, but this is critical for ensuring that I’m not using YOUR phone to open up accounts.
The Possession check can be done in a few different manners and Prove has quite sophisticated methods of accomplishing this, but the one most people are familiar with is the SMS OTP. Your bank may send you a text with four to nine digits and ask you to submit that ‘one-time password’ to the website – this allows them to confirm with a relatively high confidence that you are actually holding your phone. It’s important to note that an SMS can be shared through social engineered attacks. The outcome for Possession is True/False.
The Reputation check looks at what kind of activity has been seen on the phone recently. Indicators of risky phone numbers include Nonfixed VoIPs, as data on these line types is limited and the barrier to acquiring an account is much lower than others, and recent SIM swaps, as a bad actor can have taken over the phone. Prove has created a heuristic model that uses a plethora of signals to assign each phone number a score from 0 to 1000, where 0 is very risky, and 1000 has no risk we can identify from a Reputation standpoint.
The Ownership check confirms whether or not an individual is associated with a phone number. To do this, customers provide some PII (Personally Identifiable Information), that is used to confirm an association with the phone number. The outcome for Ownership is True/False.
Types of Fraud
While there are many different types of fraud, PRO focuses on third-party fraud, also known as identity theft. For example, say I want to open a credit line with my neighbor’s information so that I’m not held responsible for paying the card back. In this scenario, I’ll open an account using my neighbor’s phone number, which has a good reputation because she hasn’t been utilizing her phone for risky activity, and I know my neighbor’s PII, so I’m able to tie it to her phone number – ownership checks out.
However, because I’m not physically holding her phone, I won’t receive the OTP that’s sent to the phone to check for possession, and no cryptographic bind has been established – in this case, the possession check returns a ‘False’ value and stops the fraud. While there are ways for me to receive the OTP via SIM swapping and social engineering, we know the phone hasn’t been SIM swapped because it has a good reputation, and let’s assume my neighbor is knowledgeable about social engineering and doesn’t fall prey to my attempts to obtain the OTP she received.
PRO is NOT designed to catch first-party fraud, which is categorized as a person committing fraud as themselves. Consider that I, the fraudster, am perpetrating fraud in my own name. I’ll open an account using a phone number that isn’t used for risky activity but has been tied to me so that it passes the reputation and ownership checks.
Because it’s my real phone, I’ll be able to enter the OTP that’s been sent, and a cryptographic bind has been established, ensuring I pass the possession check. While not designed to catch first-party fraud, Prove can provide a detailed evidence trail that will discourage (or help relying parties identify) first-party fraud: e.g. "This transaction took place on your iPhone 15 at this time and day", essentially a 'digital watermark'.
Risk Indicator Modeling
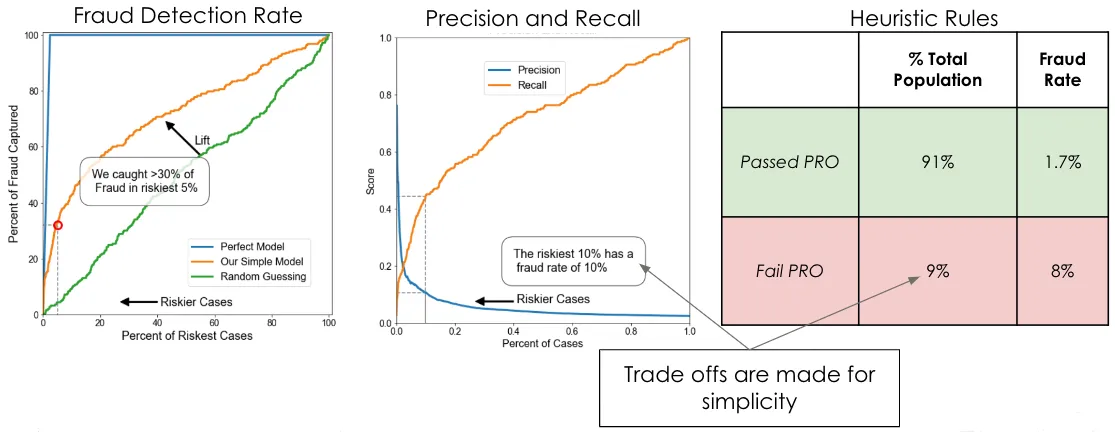
Although our products are heuristic-based, we use machine learning (ML) to build gains charts to highlight the potential fraud capture capabilities. In other words, if we look at the number of applications that Prove deems to be risky, we see that we’re able to correctly identify fraudulent transactions while minimally affecting good applicants.
There are many metrics we can use to discuss fraud capture, but some are easier to understand than others, and we need to be conscious of this when presenting to a non-technical audience. Our team performs ML to help determine which signals may be most useful for a particular client and their fraud scenarios; we can then highlight why those signals were selected with visuals tailored to the audience (e.g., projected revenue or pass-through rates). More often than not, our audience consists of product stakeholders as opposed to data experts, so we have a few different tools at our disposal, depending on who we’re having conversations with.
Using accuracy can be helpful, but the data sets we work with tend to be undersampled with fraud. Fraud tends to make up a very small portion of a data set, typically less than 3%. Say we’re working with a set that has a 2.6% fraud rate, and we find we have an accuracy of 80% – this means that 80% of the time, we can correctly classify whether a transaction was good or fraudulent. However, this doesn’t tell us much about how the model is doing because we could classify all fraudulent transactions as good and still retain an 80% accuracy rate.
Precision and recall can be useful because they give us more information on how the model determines good vs. fraudulent, not simply whether the model is correct (as accuracy does). Precision tells us what percentage of total predicted fraud was classified correctly, and recall tells us what percentage of total actual fraud was caught by the model. These can be helpful but difficult to explain and can be easily misconstrued by those not familiar with the terminology. For the same population, we could have a precision rate of 0.07 and a recall rate of 0.9. While these numbers aren’t incorrect, they don’t quite tell a comprehensive story and can be misinterpreted as accuracy. Precision is low because the model is over-classifying good transactions as fraud and only correctly classifying 90% of the fraud. If clients take this at face value, they will see that we are adding friction to a lot of their good population but not catching a lot of the fraud – which is the worst-case scenario.
We’ve found that using gains charts is a great way to convey results in an easily digestible manner. A gains chart measures how much better a model performs than random guessing. For the same population with an 80% accuracy rate, we can say that we captured 30% of the fraud by adding friction to only 5% of the population. Random guessing would have us capturing 5% of the fraudulent population, so in this instance, we have a 6x multiplier capture rate.
Data Challenges
There are many challenges that come with working with fraud data that affect the industry at large - these are not unique to Prove.
- Appropriately labeled fraud can be a pain point as there are different levels of maturity over classifications of fraud as well as different organizations and systems.
- In order for us to study fraud, we actually need to go back in time to the moment the fraud was committed. Knowing what phone activity and identity associations are today is essentially useless, so while we have the ability to look back at a moment in time, our retro capabilities are limited and decline with age.
- Having as much knowledge about our customer implementations is important as fraud looks different depending on what channels are available, where Prove products are in the flows, and what checks are happening before PRO, but we often don’t have insight into this information.
Modeling Challenges
The goal of modeling is to find the most effective features and signals in Prove’s products to stop specific client fraud.
- Logistic Regression is our main approach to modeling; we prefer to keep it simple to allow easy translation to non-technical stakeholders and often need to be able to transition to heuristic rules for clients.
- Correct fraud tagging provides better accuracy for models
- Data is often imbalanced (<3% fraud) OR a client may attempt to test us by throwing a large portion of untagged fraud into a file. Conversely, we’ve seen the opposite problem where fraud is over oversampled, but true production sampling is not clear.
- The possession check aspect of a real-time transaction can’t be simulated – we simply can’t look back in time and test whether a transaction would’ve passed a possession check.
- In Production, PRO is proactively stopping fraud, so it’s hard to measure fraud because we don’t get to see it come to fruition.
Despite these limitations, Prove is typically able to show a significant improvement in fraud capture and/or pass rates over our client’s existing approaches. Moreover, we are able to indicate an additional lift in performance when going live in production as possession checks will occur. Based on our experience with hundreds of client implementations, we can provide guidance on the range of expected lift that possession checks will yield. Finally, when we go live in production, we test a small sample population to validate that our PRO methodology is effective before deploying to the full user population.
Conclusion
Overall, Prove has been able to attain a 75% fraud reduction relative to the attack rate for our customers. There are quite a few different tools at our disposal, but we tend to utilize metrics that are easily understood by a broad audience. Types of fraud that occur, how our products are utilized, and any fraud controls our clients currently have in place can impact the performance of Prove's solutions in implementing the PRO methodology.
Bad actors are always coming up with new ways to commit fraud and so we’re continuously learning and researching how to best prevent it, developing new products, and creating best practices. It’s challenging to keep up with new attack vectors, but understanding how fraud is carried out puts Prove in a great position to stop it.
(1) “New FTC Data Show Consumers Reported Losing Nearly $8.8 Billion to Scams in 2022”, FTC.gov, February 23, 2023 https://www.ftc.gov/news-events/news/press-releases/2023/02/new-ftc-data-show-consumers-reported-lo sing-nearly-88-billion-scams-2022
The modern
way of proving identity
Trusted by 2500+ leading companies to reduce fraud and improve consumer

As a Data Scientist with a passion for using data to help others solve problems, Sophia loves digging deep into data to discover patterns and phenomena. With a proven ability to translate data insights into actionable strategies, she enjoys working closely with non-technical teams and individuals to understand their goals and pain points and providing data-backed solutions.
Keep reading
 Read the article: How to Achieve More B2B Customer Growth With Prove Pre-Fill® for Business
Read the article: How to Achieve More B2B Customer Growth With Prove Pre-Fill® for BusinessProve Pre-Fill® for Business provides a comprehensive solution for organizations that want to onboard businesses by delivering faster onboarding, a decrease in abandonment, and a reduction in fraud (relative to attack rate).
 Read the article: Account Takeovers: The Silent Revenue Killer
Read the article: Account Takeovers: The Silent Revenue KillerAccount takeover (ATO) fraud is rapidly becoming one of the biggest threats facing digital marketplaces and gig platforms. Learn how ATO attacks work, why they are accelerating, the latest fraud trends and statistics, and how continuous identity verification helps organizations prevent account takeovers while protecting revenue, customer trust, and user experience.
 Read the article: The Silent Drain: How SMS Pumping Is Bleeding Digital Marketplaces Dry
Read the article: The Silent Drain: How SMS Pumping Is Bleeding Digital Marketplaces DrySMS pumping fraud is silently increasing verification costs for digital marketplaces by exploiting OTP workflows. Explore how these attacks operate, why traditional SMS authentication is failing, and how proactive phone intelligence can prevent fraud before an SMS is sent.

Trusted by 2000+ leading companies to reduce fraud and improve consumer experiences, Prove is the world’s most accurate identity verification and authentication platform.



